Избавляемся от дубликатов в pandas
Дубликаты в данных могут быть причиной ошибок при анализе и обработке информации. Они могут искажать результаты и приводить к некорректным выводам. Поэтому очень важно уметь идентифицировать и удалять дубликаты в данных. Ну а подробнее про pandas дубликаты Вы можете почитать на сайте: it-sobes.ru
Один из способов работы с дубликатами в Python — использование библиотеки pandas. Pandas предоставляет большое количество методов для работы с данными, в том числе и методы для идентификации и удаления дубликатов.
Как найти дубликаты в pandas
Перед тем, как начать удалять дубликаты, необходимо их идентифицировать. Для этого можно воспользоваться методом duplicated() в pandas. Этот метод возвращает логический массив, указывающий на то, является ли каждая строка дубликатом или нет.
«`python import pandas as pd # создаем DataFrame с дубликатами data = {‘A’: [1, 1, 2, 3, 3], ‘B’: [‘foo’, ‘foo’, ‘bar’, ‘baz’, ‘baz’]} df = pd.DataFrame(data) # проверяем наличие дубликатов duplicates = df.duplicated() print(duplicates) «`
Результат выполнения кода выше будет следующим:
«` 0 False 1 True 2 False 3 False 4 True dtype: bool «`
Логический массив указывает на то, что строки с индексами 1 и 4 являются дубликатами.
Как удалить дубликаты в pandas
После того, как дубликаты идентифицированы, их можно удалить с помощью метода drop_duplicates() в pandas. Этот метод удаляет все строки, содержащие дубликаты.
«`python # удаляем дубликаты df_cleaned = df.drop_duplicates() print(df_cleaned) «`
Результат выполнения кода выше будет следующим:
«` A B 0 1 foo 2 2 bar 3 3 baz «`
Теперь в DataFrame остались только уникальные строки без дубликатов.
Удаление дубликатов по определенным столбцам
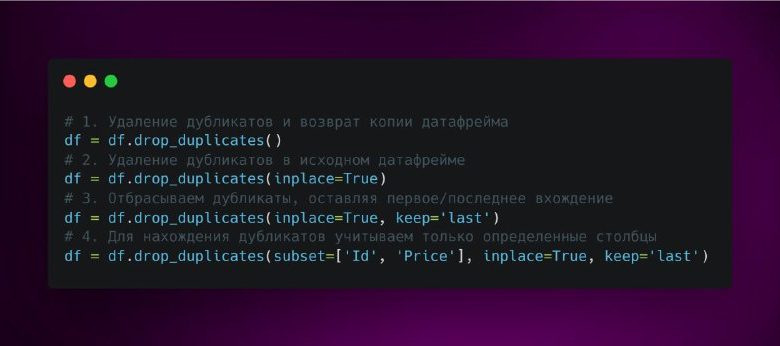
Иногда необходимо удалить дубликаты только по определенным столбцам. Для этого можно использовать параметр subset метода drop_duplicates(). Этот параметр позволяет указать, по каким столбцам нужно проверять наличие дубликатов.
«`python # удаляем дубликаты по столбцу ‘A’ df_cleaned = df.drop_duplicates(subset=[‘A’]) print(df_cleaned) «`
Результат выполнения кода выше будет следующим:
«` A B 0 1 foo 2 2 bar 3 3 baz «`
Теперь в DataFrame остались только уникальные строки по столбцу ‘A’.
Сохранение изменений в исходном DataFrame
При удалении дубликатов в pandas исходный DataFrame не изменяется. Если вы хотите сохранить изменения в исходном DataFrame, необходимо либо переопределить его, либо использовать параметр inplace=True в методе drop_duplicates().
«`python # удаляем дубликаты в исходном DataFrame df.drop_duplicates(inplace=True) print(df) «`
Теперь в результате выполнения кода исходный DataFrame df будет содержать только уникальные строки без дубликатов.
Использование дополнительных параметров
Метод drop_duplicates() в pandas имеет и другие дополнительные параметры, которые позволяют более тонко настраивать удаление дубликатов. Например, параметр keep позволяет указать, какой из дубликатов оставить.
Значения параметра keep могут быть:
- first — оставить первый дубликат;
- last — оставить последний дубликат;
- False — удалить все дубликаты.
«`python # удаляем дубликаты, оставляя последний дубликат df_cleaned = df.drop_duplicates(keep=’last’) print(df_cleaned) «`
Теперь в результате выполнения кода в DataFrame остался только последний дубликат.
ЗаключениеВ данной статье мы рассмотрели, как идентифицировать и удалять дубликаты в pandas. Использование методов duplicated() и drop_duplicates() позволяет эффективно работать с данными и избавляться от лишней информации. Это важный шаг при предобработке данных перед анализом и построением моделей.